
Il ciclo di vita di un metadato è legato al ciclo di vita della risorsa digitale, libro o articolo nel nostro caso, di cui fornisce le informazioni e del quale, come abbiamo visto nell’introduzione ai metadati, ne migliora la diffusione, la promozione e crea le premesse per monitorare le vendite e gli altri parametri bibliometrici (numero di download, numero di citazioni, ecc). I metadati si generano durante tutto il flusso editoriale: dalla fase della pianificazione editoriale a quella del controllo qualità dei metadati. Durante questa fase un tecnico specializzato individuerà gli errori eventualmente presenti e li correggerà per consentire un corretto funzionamento di tutto il sistema.

La fase della distribuzione “legge” e utilizza i metadati precedentemente creati per la promozione, diffusione e distribuzione del prodotto. L’ultima fase, quella dell’analisi, consiste nel raccogliere ed analizzare tutti i dati di diffusione e vendita della risorsa digitale per i più svariati fini, siano quelli amministrativi, come il pagamento delle royalties all’autore, siano quelli di marketing, per migliorare la promozione e la vendita del suddetto prodotto digitale, di un nuovo prodotto digitale a lui legato, o di un prodotto digitale creato ex novo.
Nell’editoria che produce risorse digitali, a differenza di quanto accade in quella tradizionale, dotata del solo supporto cartaceo, l’analisi delle vendite avviene in tempo reale grazie alle statistiche di accesso al prodotto. Questo permette maggiore dinamicità tra la fase di distribuzione e quella di analisi aumentando non solo i benefici per il prodotto digitale analizzato ma anche quelli relativi alla pianificazione editoriale di un nuovo prodotto.
Non è da dimenticare, tuttavia, che anche all’interno dell’editoria accademica è ancora molto diffuso il prodotto in formato cartaceo, in particolare nelle Humanities. In questo caso, così come avviene nell’editoria cartacea, la fase di raccolta dei dati necessiterà di un periodo di tempo più lungo.
In base alle informazioni che descrivono, i metadati possono essere organizzati in quattro aree: identificazione, responsabilità, diffusione e descrizione.
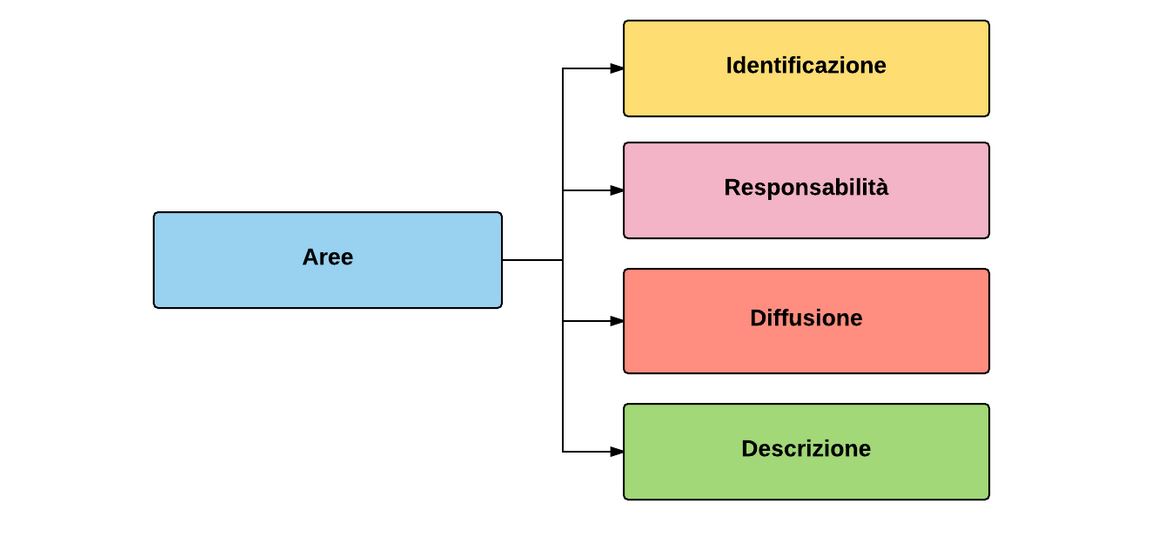
L’area identificativa serve per identificare in maniera univoca il prodotto digitale o cartaceo. Nel caso del libro digitale l’identificazione avviene solitamente tramite il DOI ovvero l’identificatore dell’oggetto digitale. Ma nel caso in cui il prodotto sia solo cartaceo e non abbia una edizione digitale l’area identificativa sarà occupata dall’ISBN ovvero un numero che identifica a livello internazionale quel titolo. Esistono anche altri codici identificativi come l’ISSN, codice internazionale che identifica le pubblicazioni in serie sia a stampa sia in formato digitale.
L’area delle responsabilità fornisce informazioni riguardanti l’autore principale dell’opera e eventuali altri autori di contributo secondario. In alcuni schemi di classificazione, come Onix, esistono delle liste controllate dotate di specifici codici da inserire in base alla posizione ricoperta dall’autore.
L’area della diffusione fornisce informazioni su chi finanzia la risorsa digitale, sulla creazione della stessa e sulla diffusione di quest’ultima. Informa, inoltre, sui diritti intellettuali della risorsa. Al suo interno vi è una sotto area, presente solo in alcuni standard, che fornisce le informazioni relative alla registrazione del DOI.
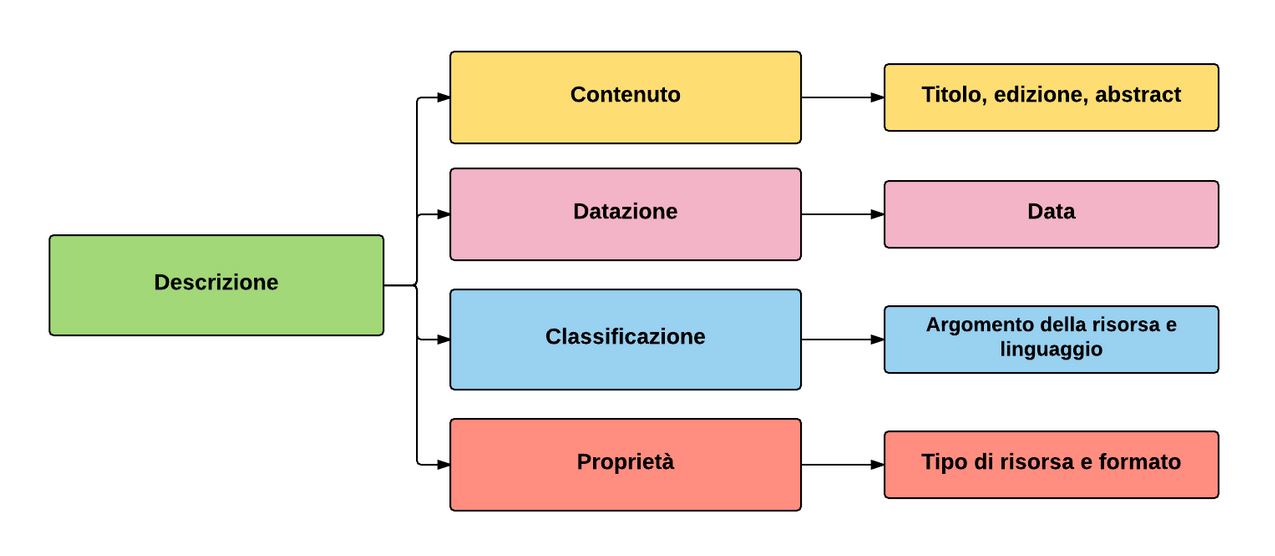
L’area della descrizione, infine, contiene le informazioni descrittive della risorsa digitale: il titolo, l’abstract, la data, l’argomento della risorsa, la lingua e, infine, il tipo e il formato della risorsa. Possiamo immaginare questa area suddivisa a sua volta in quattro sotto aree: contenuto, datazione, classificazione, proprietà.
Le aree dei metadati saranno approfondite nei prossimi articoli quando ci soffermeremo sull’analisi degli standard Dublin Core, HighWire Press, Og:, Onix mEDRA e Datacite.
Per approfondire:
The Metadata Handbook
I Metadati nell’archivio digitale





